バッチ処理のレビュー時の観点や、運用時にどのように問題対応を行うのかなど、バッチ処理について個人的に思うことをまとめてみます。
基本的にJava屋なので、Javaの世界からの思っていることと捉えてもらえれば良いかと思います。
1. 1. 目次
以下の内容について記載しています。
- 1. 1. 目次
- 2. Javaのバッチ処理の実装パターンについて
- 3. JSR-352 の処理モデルについて
- 4. ジョブスケジューラーについて
- 5. グルー言語
- 6. レビュー時の観点について
- 7. テスト観点について
- 8. エラー発生時の調査、対応フロー
- 9. 参考
2. Javaのバッチ処理の実装パターンについて
個人的な観測範囲では以下のようなバッチ処理のライブラリを使があります。
2.1. public static void main(String[] args) を実装実行するパターン
シンプルなツール等だとこのケースもあります。
jar に固められていて、Windowsであれば、バッチファイルや、powershellスクリプト等から実行され、
Linux上からであれば、Bash等から実行されます。
大規模な業務システムだと、その業務システム独自のフレームワークがあり、サブクラス側にmain処理は書くが、大体必要なことは親クラスがやってくれる。
という作りをしているケースが多いです。
2.2. Servetや、WebAPIがバッチ処理のエンドポイントになっているケース
Servetや、WebAPIがバッチ処理のエンドポイントになっているケースです。
DB接続にJ2EEサーバーのConnection Poolの機能が使えるので、バッチ処理で、コネクションを貼り過ぎてしまうといったトラブルが回避できます。
2.3. スケジュール実行のためのAPIが使われるケース
J2SEのAPIとして、以下のようなAPIが提供されています。
10年くらい前に、Timerを使ってJobの実行時間定義は、RDBで定義して、Jobをスケジュール起動するアプリケーションを見たことがありますが、個人的には良い仕組みとは思えませんでした。
2.4. スケジュール実行のためのライブラリが使われるケース
Spring Boot にはこの辺りのAPIを内部的に使っているであろう。@Scheduledというアノテーションがあります。
Dropwizardにも、dorpwizard-jobs というライブラリがあります。
* dropwizard-jobs/dropwizard-jobs: Scheduling / Quartz integration for Dropwizard
また、今回調べていて知りましたが、Quartzというライブラリもあるようです。
J2SEの標準ライブラリを使いやすくしたものですが、個人的に、スケジュールコントロールするアプリケーションは、別で存在した方エラー処理、リトライ等を細かく制御できると考えてます。
Javaアプリケーション上で、スケジュール実行も制御するのは先入観かもしれませんが、あまりメリットがないように思います。
2.5. JBatch関連のフレームワーク
JSR-352 Javaのバッチ処理のフレームワークに関する仕様があります。
元々 SpringBatch があってそれを仕様化したものが、JSR-352になります。
起動方法やスケジューリング機能ではなく、バッチの内部処理を仕組み化したフレームワークです。
partition 等は自前実装が大変なケースが多いです。この辺りの仕組みを得られるのはメリットが大きいと思います。
ライブラリと、参考記事へのリンクを貼っておきます。
-
ライブラリ
-
spring-projects/spring-batch: Spring Batch is a framework for writing offline and batch applications using Spring and Java spring-batch JOB定義はXMLで作成していく。
-
j-easy/easy-batch: The simple, stupid batch framework for Java
XMLを書かなくても、spring-batch風のコードを実装できるライブラリ。
SpringBootや、DropwizardのCLIと組み合わせて実装すると、良い感じに使えます。
-
-
参考
2.6. CLIコマンドラインライブラリ
コマンドラインからバッチ処理を実行する場合、コマンドラインParserライブラリがあると、引数を取るバッチ処理を作成する場合、実装が簡単になります。
picocli のWikiに各JavaのCLI関連のライブラリのリンクが記載されていたので、リンクを貼っておきます。
- CLI Comparison · remkop/picocli Wiki
今まで、Args4Jを良く使っていましたが、picocli良さそうに思いました。
コマンドラインのHelpがカラー表示されるあたりはDjango臭がして良い感じです。
3. JSR-352 の処理モデルについて
JSR-352の処理モデルにアイテムベースの処理、タスクベースの処理 がありますが、JSR-352を使っていなくても、この辺りの考えが実装には落としこまれそうに思いました。
それぞれの処理モデルについてまとめてみます。
3.1. タスクベースの処理 (タスクレットモデル)
全体で一括コミットで処理するモデルです。
内部で、コミットすることで分割コミットもできますが、基本的にAll or Nothing で処理をするモデルになります。
-
メリット
- 再実行時は、Jobをリランするだけで、復旧できる。
- 実装はシンプルなので、処理の見通しが良くなる。
-
デメリット
- 大量データの処理を行うとAll or Nothing の処理であることが原因で、リソースが枯渇する場合がある。
3.2. アイテムベースの処理 (チャンクモデル)
件数ベースでの処理を実現するためのモデルです。
指定した件数で、コミットする機能があり、少しずつコミットをして処理を進めるタスクが実限できます。
-
メリット
- 大量データを処理するバッチの実装をシンプルにできる。
-
デメリット
- 実装がタスクレットに比べて複雑
- ジョブを再実行する場合、エラーデータのみを処理するなどの考慮が必要
3.3. 並列処理と多重処理
Spring Batch スケーリングと並列処理 - リファレンス には、以下4つのカテゴリの、並列処理が記載されています。
- マルチスレッドステップ (単一プロセス)
- 並行ステップ (単一プロセス)
- リモートステップのチャンキング (マルチプロセス)
- ステップの分割 (シングルまたはマルチプロセス)
Spring Batch を使っていなくても、処理の方式は参考にできます。
パーティショニング による処理の分割は、個人的には使用頻度が高そうに思いました。
4. ジョブスケジューラーについて
バッチ処理の実行時間帯をコントロールしたり、バッチ処理の起動条件等をコントロールするツールです。
以下のQiita記事に主要なジョブスケジューラはまとまっている感じでしたので、リンクを貼っておきます。
基本的に、Cron実行や、Windowsのジョブスケジューラーを使った定期実行のスケジューリングが、煩雑になってきたら、より重厚なスケジューラに移行していくのかなと思います。
5. グルー言語
バッチ処理のジョブスケジューラと、バッチ本体処理の起動までを紐付けするが、個人的にはグルー言語だと思っています。
グルー言語 - Wikipedia を引用しますが、以下の通り記載されています。
グルー言語 (英: glue language) とはプログラミング用語のひとつであり、ソフトウェアコンポーネント同士を結びつけることを主眼としたプログラミング言語の総称である。「グルー」とはにかわ状の接着剤のことを意味する。
Windows環境でJavaのバッチ処理を動かす場合は、batファイル(CMDスクリプト)、PowerShell がタスクスケジューラーからJavaのコマンドを実行するために使われ、
Linux環境では、シェルスクリプト がバッチ処理実行のためのグルー言語として使われることが多いかなと思います。
高機能なジョブスケジューラー上でも、スクリプトの記入欄があって、バッチ処理を実行するための処理に使ったり、戻り値を判定するために使われたりもします。
6. レビュー時の観点について
以下のようなチェック観点をレビュー時には意識しています。
基本的に、JSR-352 でいうとタスクレットモデル、チャンクモデルの処理に関するレビュー観点になります。
6.1. 前提
以下の状況下でのレビュー観点になります。
-
RDB への CRUD が中心
-
cron 等 の job sheduler 起動
-
jobnet が組まれていない。 (後続 job がない。)
-
日次で変化が発生する、データ集合を処理する。
-
同時起動数は1で、パラレル実行は発生しない。
-
ユーザー側システム部門が、IT ベンダーに対してのチェックを行う状況。
6.2. チェック観点
6.2.1. Transaction の Save Point の単位
データ集合を処理する際の、Transaction の Save Point を明確にします。
1件ずつコミットなのか? 一括でコミットなのか?
6.2.2. Shedule の設定
どのような起動間隔で実行するのかを明確にします。
6.2.3. リトライ時の動作
Shedule 設定に対して、起動予定時刻に起動したが、異常終了した場合の再実行時の期待動作を確認します。
単純な再実行で動かない場合、どのようなSE作業をしたら希望通りに動くのか? とその動作の合意はとれているのか? が重要になります。
動作には、Transaction の Save Point の単位 、Shedule の設定 が大きく影響します。
リトライ時の期待動作が実現できない場合は、Save Pointの見直したりするかと思います。
6.2.4. 異常系処理の確認
-
異常系時の振る舞いの確認
RDB アクセスであれば、クエリ発行ポイントでエラー(これはシステムエラー、アプリケーションエラー双方)が発生した場合、どのような振る舞いとなるのか?を確認します。
ロールバックが期待通り行われるのか?が重要な確認ポイントになります。 -
監視アラート
Logポリシーで監視アラートも決まるケースもあり、その場合は必要ありません。
Logポリシーと監視通知が切り離されている場合は、何を監視アラート通知対象にするのか、何を対象外にするのかを決めておきます。
6.2.5. Logポリシー
どのようなポリシーで、ログを出してるのかを確認します。
LOG LEVEL と、出力内容について
例えば、LOOP内のログは、ループの単位がわかる、データ項目値を出力しているか等。
Logに、データ特定に必要な情報がない場合、エラーになったことはわかるがエラーとなった原因のデータがわからないという状況になるので、データを特定できるパラメータの設定は必須です。
6.2.6. 集合データの取得のポリシー
どういうポリシーでデータを取得しているのかを確認します。
あまりデータ精度が高くなかったりする状況で、抽出条件が甘いと、バッチ処理内の後続処理の発行クエリでデータがとれなかったり変なデータがとれたりします。
前処理でチェックしたデータの前提条件は確認しないのか、それともするのか等を確認しています。
6.2.7. 処理対象データ取得する際のSQLの実行計画等の取得有無と、テストでの評価
バッチ処理では、集合データ取得処理(バッチの処理対象データの取得)が含まれるケースがあります。
バッチの性質にもよりますが、このデータ取得SQLは、データ処理件数に応じて、遅くなる傾向があります。
実行計画などを取得し、事前にチューニングをしているのか、負荷テストなどの計画を立てているのかを確認します。
6.3. 確認の仕方で気をつけていること
指摘ではなく、疑問系で、今回作成していただいた週次のスケジューラーバッチで、リトライ動作の観点で気をつけたところはありますか?
みたいな形で聞いても効果はあるかと思います。
この頁に記載していないが大事な要素にレビュイー側が気がついてくれるケースがあります。
7. テスト観点について
テスト観点はレビュー時の観点について での確認ポイントに対しての妥当性検証になります。
7.1 Transaction の Save Point の単位
Taransaction のSave Point の単位の妥当性検証しては以下のようなテストの設定が考えられます。
- 指定したコミット件数でデータのコミットが行われているか?
- エラーで落ちた際に、指定しているSave Pointまでデータがロールバックされているか?
7.2. Shedule の設定
指定したスケジュールで、正しくバッチが起動していることを確認します。
- 指摘した稼働時刻にバッチが起動しているか?
- 開発環境と、本番環境でスケジュール設定が別途必要であれば、それぞれのテストを計画しているか?
7.3. リトライ時の動作、常系処理の確認
ここは、異常時の復旧処理に関するテストを実施することになるので、まとめて記載します。
以下をテスト観点として設定する必要があります。
- エラー時に監視アラートの対象になり、検知できるか?
- 検知後にリトライができるか?
- 想定外エラーの場合も原因が特定できる情報がログなどに出力されるか?
- 運用手順正を準備している場合、想定した運用手順で復旧ができるか?
7.4 ログ
ログに関するテスト観点としては以下を設定するべきです。
- 何件処理した等の必要なログが出力されているか?
- 不必要な情報が出力されていないか?
必要な情報とは、ログを出し過ぎるという意味での不必要と個人情報に当たる情報を出力していないという観点があるかと思います。
7.5 集合データの取得のポリシー
データ集合に対してのテスト観点として以下が想い浮かびました。
- ポリシーに合致しないデータをパターン別に準備してテストしているか?
- いっそ本番環境でデータ取得クエリを実行して想定外のデータが取得できていないか?
7.6 処理対象データ取得する際のSQLの実行計画等の取得有無と、テストでの評価
データ負荷に関するテストとしては以下が考えられます。
- 負荷テストを計画、実施しているか?
- データ増加量に対しての見積もりを実施しているのならばその見積もり妥当性を検証しているか?
7.7 チェックリストにする
上記の項目と正常系のパターンをまとめてチェックリストにしてみます。
| 正常系/異常系 | 内容 |
|---|---|
| 正常系 | 処理対象0件の挙動を確認しているか? |
| 正常系 | 処理対象1件の挙動を確認しているか? |
| 正常系 | 処理対象2件のの挙動を確認しているか? |
| 正常系 | 指定したコミット件数でデータのコミットが行われているか? |
| 正常系 | 指摘した稼働時刻にバッチが起動しているか? |
| 正常系 | 開発環境と、本番環境でスケジュール設定が別途必要であれば、それぞれのテストを計画しているか? |
| 正常系 | ポリシーに合致しないデータをパターン別に準備してテストしているか? |
| 正常系 | いっそ本番環境でデータ取得クエリを実行して想定外のデータが取得できていないか? |
| 正常系 | 負荷テストを計画、実施しているか? |
| 正常系 | データ増加量に対しての見積もりを実施しているのならばその見積もり妥当性を検証しているか? |
| 正常系 | 何件処理した等の必要なログが出力されているか? |
| 正常系 | 不必要な情報が出力されていないか? |
| 異常系 | エラーで落ちた際に、指定しているSave Pointまでデータがロールバックされているか? |
| 異常系 | エラー時に監視アラートの対象になり、検知できるか? |
| 異常系 | 検知後にリトライできるか? |
| 異常系 | 想定外エラーの場合も原因が特定できる情報がログなどに出力されるか? |
| 異常系 | 運用手順正を準備している場合、想定した運用手順で復旧ができるか? |
8. エラー発生時の調査、対応フロー
バッチ処理がリリースされ運用フェーズになると、まずなんらかのエラーが発生します。
エラーは監視アラートツールでメールや、オンコール、Chatツールなどに通知され、その通知をトリガーに調査やなんからの対応をしていくことになります。
障害発生時の対応フロー(初期対応、本格対応、再発防止) - 勘と経験と読経 に、初期対応、本格対応、再発防止の3つのフレームが記載されていて、参考になったので、 本格対応 > 恒久対応として、バッチエラー発生時の対応フロー図を作成してみました。
- バッチエラー発生時の調査、対応フロー図
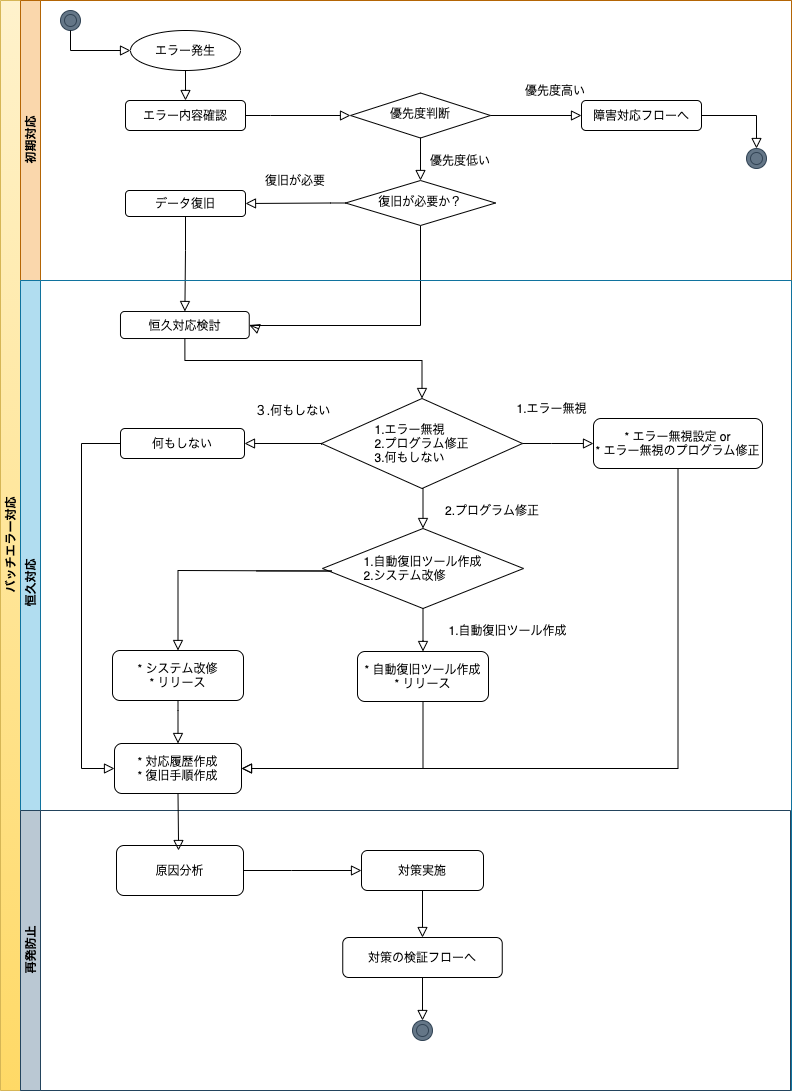
8.1. フロー図の補足説明
フロー図について、補足説明を記載します。
8.1.1. 初期対応フレーム
エラー内容確認から、データ復旧までを初期対応フレームとしています。
-
エラー内容確認
Javaのバッチ処理であれば、まともに実装されていれば、エラー情報としてスタックトレースを出力しています。
まずスタックトレースを見て、エラー発生箇所を特定します。
またに、ログにのみスタックトレースが出力されていて、そのログの取得に時間がかかる。
酷いケースだと、ログにすらスタックトレースが出力されないケースがあります。このスタックトレースが出力されないケースは、周辺のログ情報からエラーの原因を推測するか、
エラーが再現するオペレーションが特定できている場合は、扱っているデータを確認すると原因が特定できることがあります。 -
優先度判断
初期対応フレームは判断の速度が必要になります。エラー内容確認と、優先度判断等は、自分よりもシステムに詳しい人がいるなら、まず詳しい人に聞くのも重要です。
エラーになったバッチで、大まかな優先度が決まるケースもあります。
タスクレットモデルのバッチが、ジョブフロー上で動いている場合、後続バッチも動いていない可能性が高く、復旧優先度が高まります。 -
復旧が必要か?の判断
エラーとなったから復旧が必ず必要かというとそういう訳ではなく、実行タイミングの問題で処理済のデータを再度処理しようとしてエラーになる等のケースもあります。
プログラム実装で考慮できていないデータ状態があるということなので、厳密にプログラムバグですが、ヒヤリハットで実データへの影響はありません。 -
データ復旧
データ復旧が必要な場合は、バッチ処理のモデルへの理解度が、復旧手順の作成スピードを早めます。 以下、ざっくり対応を記載していますが、チャンクモデルで、処理途中にミットを行うようなケースがあると、復旧のパターンは複雑になります。- タスクレットモデル
エラー原因を特定、解消して再実行。 - チャンクモデル
エラー発生したデータ以降の処理が行われているか確認。行われている場合は、エラー発生したデータのみを再実行対象としてバッチをリランする。 行われていない場合は、エラーが発生したデータ以降のデータも含めて、再実行対象としてバッチをリランする。
- タスクレットモデル
8.1.2. 恒久対応フレーム
恒久対応方法の検討から、対応実施、対応履歴作成、復旧手順作成までを、恒久対応フレームとしています。
-
恒久対応方法検討
恒久対応方法として以下があると考えました。
改修のコストと、発生した際のコストを天秤にかけて、どの対応をとるのか決めていきます。- エラー無視
対象エラーを監視アラートの対象から外します。
アラートを送出するツールの設定変更。プログラム回収をして、アラート通知する処理を削除するなどシステムによって実施内容は異なります。 - システム改修
エラーの発生原因そのものを解消するためシステム改修を行う。
もしくは、発生時の自動復旧を実施するツールを作ります。
アプリケーションサーバ負荷や、DBアクセスの処理の滞留でエラーになるケースは、自動復旧するツールを作ると手がかからなくなります。 - 何もしない
発生頻度が低く、優先度が高くないエラーは何もしないで良いです。ROI算出した結果、リスク許容と判断したものになります。
- エラー無視
-
対応履歴作成、復旧手順作成
1つの文書でまとまっているケース、文書が分かれているケースがあるかもしれませんが、それぞれ作成します。
何もしない場合も、忘れた頃に同じ事象が発生するので復旧手順を作成しておきます。
8.1.3. 再発防止フレーム
恒久対応後は、原因分析と再発防止策の実施になります。
-
原因分析
原因分析には様々な手法があります。個人的にはなぜなぜ分析は実施したことがありますが、その他の手法は実施経験がありません。
なぜなぜ分析のアンチパターンになっていなそうで、個人攻撃になっているをよく目にします。
Project Fabreのスライドの内容が刺さりました。 -
対策実施
原因分析の結果をもとに、対策を実施します。対策を実施後は、実施した対策の効果測定を実施する必要があり、このフロー上ではなくそれは施策の効果測定フロー行きになるのかと思います。
9. 参考
以下、参考にした記事になります。
-
JSR-352
-
ジョブスケジューラとグルー言語
-
一般的なバッチ処理
-
障害対応
-
原因分析
- 小倉仁志の「なぜなぜ分析」 ちょっとしたコツ|有限会社マネジメント・ダイナミクス
- ヒューマンエラー - Wikipedia
- 失敗学 - Wikipedia
- Microsoft PowerPoint - 原本130809経営課題抽出と解決の手法(保健医療経営大学)
- どこがマズイ?なぜなぜ分析 簡単な例でわかる | 論理思考補足編 | ロジカルシンキング研修.com
- FMEA - Wikipedia
- 根本原因解析 - Wikipedia
- なぜなぜ分析の良書籍: プログラマの思索
本来のなぜなぜ分析では、最後の5回目のなぜで、心理的要因にたどり着くものらしい。 例えば、油断、思い込みなど。
以上です。
コメント